Manipulating Jack/Ladspa Audio processing graphs from Bwise
The objective here is to automatically create a usable tcl script like this:
prodphase3a.tcl:
exec bash -c export LADSPA_PATH=/usr/lib64/ladspa/
set cc 0
catch {
exec jack-rack -c 2 -s innoi innoi -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -c 2 -s 4cdplay 4cdplay_pro -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -c 2 -s lowmidspea lowmidspea14 -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -c 2 -s compdrive compdrive -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -c 2 -s dellex dellex -x [incr cc 20] -y $cc -w 584 -l 1170 &
after 500
exec meterbridge -t dpm -r 0 -c 2 1 2 -n in &
}
after 500
catch "exec jack_connect system:capture_1 jack_rack_innoi:in_1"
catch "exec jack_connect system:capture_2 jack_rack_innoi:in_2"
catch "exec jack_connect system:capture_1 in:meter_1"
catch "exec jack_connect system:capture_2 in:meter_2"
catch "exec jack_connect jack_rack_innoi:out_1 jack_rack_4cdplay:in_1"
catch "exec jack_connect jack_rack_innoi:out_2 jack_rack_4cdplay:in_2"
catch "exec jack_connect jack_rack_dellex:out_1 system:playback_1"
catch "exec jack_connect jack_rack_dellex:out_2 system:playback_2"
set u ./b
catch {
after 1000
exec jack-rack -s del2 -c 2 del2 -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -s del3 -c 2 del3 -x [incr cc 20] -y $cc -w 584 -l 1170 &
}
#gets stdin
catch {
exec meterbridge -t dpm -n bridge -r 0 6 7 8 9 10 11 12 13 &
exec meterbridge -t dpm -r 0 -c 2 1 2 -n om &
exec meterbridge -t dpm -r 0 -c 2 1 2 -n om2 &
exec meterbridge -t dpm -r 0 -c 2 1 2 -n out &
}
after 1500
catch "exec jack_connect jack_rack_innoi:out_1 jack_rack_4cdplay:in_1 "
catch "exec jack_connect jack_rack_innoi:out_2 jack_rack_4cdplay:in_2 "
catch "exec jack_connect jack_rack_4cdplay:out_1 jack_rack_del2:in_1"
catch "exec jack_connect jack_rack_4cdplay:out_2 jack_rack_del2:in_2"
after 500
catch "exec jack_connect jack_rack_del2:out_1 jack_rack_del3:in_1"
catch "exec jack_connect jack_rack_del2:out_2 jack_rack_del3:in_2"
catch {
exec jack-rack -c 2 -s aaa aaa_lim -x [incr cc 20] -y $cc -w 584 -l 1170 &
}
catch {
exec jack-rack -c 2 -s par par_tube -x [incr cc 20] -y $cc -w 584 -l 1170 &
}
after 1500
for {set i 6} {$i<=13} {incr i} {
append o [exec jack-rack -c 2 -s $i Autom/b$i -x [incr cc 20] -y $cc -w 584 -l 1170 &] " "
after 500
catch "exec jack_connect jack_rack_aaa:out_1 jack_rack_$i:in_1"
catch "exec jack_connect jack_rack_aaa:out_2 jack_rack_$i:in_2"
after 500
catch "exec jack_connect jack_rack_$i:out_1 jack_rack_par:in_1"
catch "exec jack_connect jack_rack_$i:out_2 jack_rack_par:in_2"
}
after 500
for {set i 6} {$i<=13} {incr i} {
append o [exec jack-rack -c 2 -s df$i df$i -x [incr cc 20] -y $cc -w 584 -l 1170 &] " "
after 500
catch "exec jack_connect jack_rack_compdrive:out_1 jack_rack_df$i:in_1"
catch "exec jack_connect jack_rack_compdrive:out_2 jack_rack_df$i:in_2"
after 500
catch "exec jack_connect jack_rack_df$i:out_1 jack_rack_$i:in_1"
catch "exec jack_connect jack_rack_df$i:out_2 jack_rack_$i:in_2"
}
after 500
for {set i 6} {$i<=14} {incr i} {
after 400
catch "exec jack_connect jack_rack_$i:out_1 bridge:meter_[expr $i-5]"
catch "exec jack_connect jack_rack_$i:out_2 bridge:meter_[expr $i-5]"
}
after 500
catch "exec jack_connect jack_rack_del3:out_1 out:meter_1"
catch "exec jack_connect jack_rack_del3:out_2 out:meter_2"
catch "exec jack_connect jack_rack_par:out_1 om:meter_1"
catch "exec jack_connect jack_rack_par:out_2 om:meter_2"
catch "exec jack_connect jack_rack_par:out_1 out:meter_1"
catch "exec jack_connect jack_rack_par:out_2 out:meter_2"
after 500
catch "exec jack_connect jack_rack_dellex:out_1 om2:meter_1"
catch "exec jack_connect jack_rack_dellex:out_2 om2:meter_2"
catch {
exec jamin -p -n jam -f ./harmo4.jam &
}
after 500
after 500
catch "exec jack_connect jam:out_L jack_rack_aaa:in_1"
catch "exec jack_connect jam:out_R jack_rack_aaa:in_2"
after 500
set u ./b
catch {
after 800
exec jack-rack -c 2 -s higpas higpasslow -x [incr cc 20] -y $cc -w 584 -l 1170 &
exec jack-rack -c 2 -s higcom higexp -x [incr cc 20] -y $cc -w 584 -l 1170 &
}
catch {
exec meterbridge -t dpm -r 0 -c 2 1 2 -n hico1 &
}
after 500
catch "exec jack_connect jack_rack_4cdplay:out_1 jack_rack_lowmidspea:in_1 "
catch "exec jack_connect jack_rack_4cdplay:out_2 jack_rack_lowmidspea:in_2 "
catch "exec jack_connect jack_rack_lowmidspea:out_1 jack_rack_compdrive:in_1 "
catch "exec jack_connect jack_rack_lowmidspea:out_2 jack_rack_compdrive:in_2 "
catch "exec jack_connect jack_rack_4cdplay:out_1 jack_rack_higcom:in_1 "
catch "exec jack_connect jack_rack_4cdplay:out_2 jack_rack_higcom:in_2 "
catch "exec jack_connect jack_rack_higpas:out_1 out:meter_1 "
catch "exec jack_connect jack_rack_higpas:out_2 out:meter_2 "
catch "exec jack_connect jack_rack_higpas:out_1 hico1:meter_1 "
catch "exec jack_connect jack_rack_higpas:out_2 hico1:meter_2 "
append o [catch "exec jack_connect jack_rack_higcom:out_1 jam:in_L "]
append o [catch "exec jack_connect jack_rack_higcom:out_2 jam:in_R "]
append o [catch "exec jack_connect jack_rack_lowmidspea:out_1 jam:in_L "]
append o [catch "exec jack_connect jack_rack_lowmidspea:out_2 jam:in_R "]
append o [catch "exec jack_connect jam:out_L jack_rack_higpas:in_1 "]
append o [catch "exec jack_connect jam:out_R jack_rack_higpas:in_2 "]
append o [catch "exec jack_connect out:monitor_1 jack_rack_dellex:in_1 "]
append o [catch "exec jack_connect out:monitor_2 jack_rack_dellex:in_2 "]
after 501
puts $o
after 1500
puts $ofrom a BWise graph, so as to rearange audio signal paths for Linux machines (maybe Windows "Jack" and Mac Jack can work too), composed of multiple interconnected "jack-rack" processing blocks, with associated DSP definition files.
For me these tcl scripts (I'll make a shorter, explained version soon) make it possible to run a great audio processing chain to correct CD files and postproduce for instance "HDtracks" high quality tracks, without having to start up all the jack-rack programs+interface by hand. These scripts gets my I7 machine running these heavy graphs reliably in a few tens of seconds, bu now want to take parts of various types of processing, and make new graphs, so I adapt BWise a bit.
First we make "dummy" bwise blocks for each file in a diretory with the effect files we want to use:
set downc 20
foreach i [glob Jackrack/*] {
newproc {} [file tail $i] i o 40 {} jack [expr 40 + 100 *($downc / 1000)] [expr 20 + ($downc % 1000) ]
incr downc 66
}Now we use bwise to select the blocks we use (for the moment) and connect them:
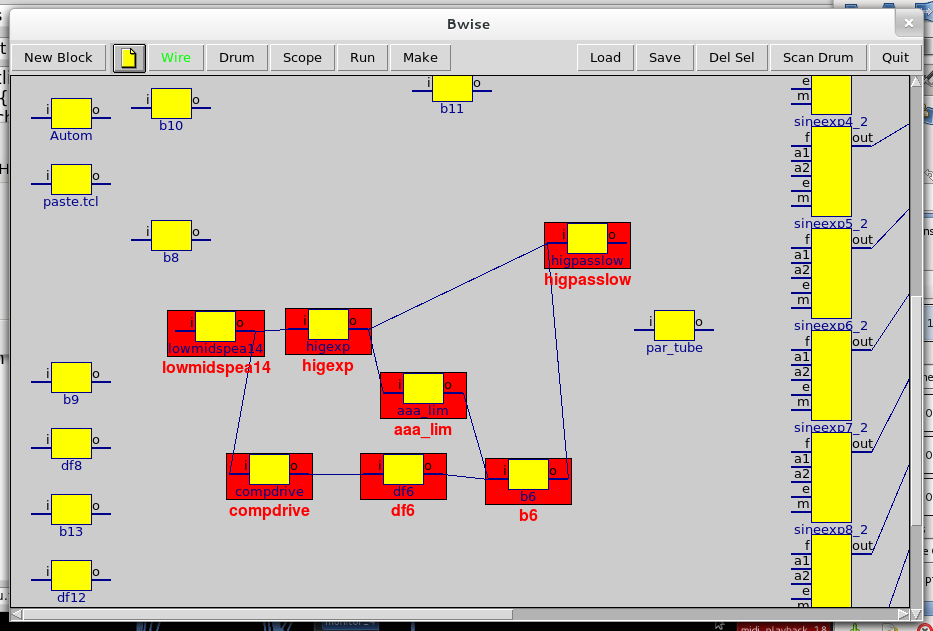
Now we can list the relevant connections:
% netlistout jack
{aaa_lim o b6 i} {compdrive o df6 i} {higexp o aaa_lim i} {higexp o higpasslow i} {lowmidspea14 o compdrive i} {lowmidspea14 o higexp i} {df6 o b6 i} {b6 o higpasslow i}and construct tcl commands to start the jack programs:
% foreach i [listunion [$mc find withtag selection0] [$mc find withtag bb]] {puts "exec jack-rack -s [set tm [block_name_fromid $i]] Jackrack/$tm"}
exec jack-rack -s aaa_lim Jackrack/aaa_lim
exec jack-rack -s b6 Jackrack/b6
exec jack-rack -s compdrive Jackrack/compdrive
exec jack-rack -s df6 Jackrack/df6
exec jack-rack -s higexp Jackrack/higexp
exec jack-rack -s higpasslow Jackrack/higpasslow
exec jack-rack -s lowmidspea14 Jackrack/lowmidspea14Of course we could make an easier list of the blocks representing "jack-rack + input file" by for instance selecting the output block (extreme right of the connected graph) called higpasslow, and use the "net_allleft" function built in later BWise versions for instance, to get all the blocks connected to the left of that block (counted once, in random output order):
% net_allleft higpasslow aaa_lim b6 compdrive df6 higexp higpasslow lowmidspea14
And then use the same puts command as above, of course even better would be to start the processing units in for instance left to right order, we'll look at a solution for such an automatically generated startup script later.
The netlist can be automatically generated since early versions of BWise, and in this case I used the label "jack" to distinguish blocks refering to the "jack-rack" blocks from other bwise blocks on the canvas, but lets also create the correct startup commands, of our non-sensical example graph:
% foreach i [netlistout jack] {
puts "catch \"exec jack_connect jack_rack_[lindex $i 0]:out_1 jack_rack_[lindex $i 2]:in_1\""
puts "catch \"exec jack_connect jack_rack_[lindex $i 0]:out_2 jack_rack_[lindex $i 2]:in_2\""
}
catch "exec jack_connect jack_rack_aaa_lim:out_1 jack_rack_b6:in_1"
catch "exec jack_connect jack_rack_aaa_lim:out_2 jack_rack_b6:in_2"
catch "exec jack_connect jack_rack_compdrive:out_1 jack_rack_df6:in_1"
catch "exec jack_connect jack_rack_compdrive:out_2 jack_rack_df6:in_2"
catch "exec jack_connect jack_rack_higexp:out_1 jack_rack_higpasslow:in_1"
catch "exec jack_connect jack_rack_higexp:out_2 jack_rack_higpasslow:in_2"
catch "exec jack_connect jack_rack_higexp:out_1 jack_rack_aaa_lim:in_1"
catch "exec jack_connect jack_rack_higexp:out_2 jack_rack_aaa_lim:in_2"
catch "exec jack_connect jack_rack_lowmidspea14:out_1 jack_rack_higexp:in_1"
catch "exec jack_connect jack_rack_lowmidspea14:out_2 jack_rack_higexp:in_2"
catch "exec jack_connect jack_rack_lowmidspea14:out_1 jack_rack_compdrive:in_1"
catch "exec jack_connect jack_rack_lowmidspea14:out_2 jack_rack_compdrive:in_2"
catch "exec jack_connect jack_rack_df6:out_1 jack_rack_b6:in_1"
catch "exec jack_connect jack_rack_df6:out_2 jack_rack_b6:in_2"
catch "exec jack_connect jack_rack_b6:out_1 jack_rack_higpasslow:in_1"
catch "exec jack_connect jack_rack_b6:out_2 jack_rack_higpasslow:in_2"In BWise one of the schedulers could be used to generate a more flow-logical order of starting the (in my case) Linux audio processing programs+interface up, but strictly BWise doesn't allow implicit multiple inputs. There is a computer-technical reason to also introduce delays. and the start the Jack processing modules up in the order in which they are connected, so that is next. The delays are to give the kernel time to do a good memory (buffer) allocation, to let the GUIs come up in peace, and to make sure the schedule for the Jck interrupts has time to stabilize. So that's next, but at least the above easily let me make a different graph with existing jack-rack files, and generate the script to start them up fully automatically!
A few practical considerations: file names with special characters being rendered as a function block, as well as numerical file names generate errors, but for the moment I'll call my audio plugin rack files decent names and put them in their own directory where they can be used as above. There is a automatic number option in the newproc procedure which could be used for multiple isntances of the same effect, and it may be necessary to make more types of audio rack-block, as for the moment I presumed thei're all "jack-rack"-s but there are a few other progams I use. Also, I've made a "subgraph" by giving the blocks at hand a label "jack" (which lets certain bwise functions filter) and I used the equivalent of the double-click to select the relevant blocks in the audio graph.
We can also select all blocks in a connected graph by going to the last block and using "net_allleft last_block_name" to get a list listing all block names once as return value.
For this example I need to adjust the block_function because when a block is evaluated, the pin names are wrong, lets also make every block output it's own name, merged with it's inputs as a flat list (just to see that the "merge" of two outputs on one input generates an error, because outputs may fork, but inputs, for obvious reasons, don't merge) and I make a global variable (blocks operate on global vars per def. in current bwise) "global schedule list" which records the names of blocks being fired (in "fire" order), so we can use the "funcprop" scheduler to create a nicer jack-rack startup script, which starts audio programs up and immedeately connect it's inputs:
set glsch {}
foreach j [ net_allleft higpasslow ] {
set ${j}.bfunc "set ${j}.o \"$j \$\{${j}.i\} \" ; append glsch $j \" \""
}
net_funprop lowmidspea14
set glsch
lowmidspea14 higexp compdrive aaa_lim df6 b6 higpasslowRight! Now we have a nice schedule list we can use for an ordered startup script.
I'll put on some updated bwise files in a while (with a nice example I'd put on before) and the startup script and something of this example, maybe with on-canvas menus to make your own script.
TV May 5 013: I wanted to start using these scripts for getting some actual work done, so I started with a little "dolby" processing graph consisting of 5 blocks, and I came up with this script to create an actual working jack graph to start the "jack-rack"s up *and* connect them like in the bwise graph I made like above (but different dir., blocks, and connections):
set glsch {}
foreach j [ net_allleft dolbycout ] {
set ${j}.bfunc "set ${j}.o \"$j \$\{${j}.i\} \" ; append glsch $j \" \""
}
net_funprop 4cdplay3
# set glsch
foreach i $glsch {
puts "catch \"exec jack-rack -c 2 -s $i $i &\""
puts "after 1000"
foreach j [net_left $i] {
puts "catch \"exec jack_connect jack_rack_$j:out_1 jack_rack_$i:in_1\""
puts "catch \"exec jack_connect jack_rack_$j:out_2 jack_rack_$i:in_2\""
}
puts "after 500"
}The nested loop first starts the next block in the schedule sequence (roughly left to right of any BWise graph), waits a second, then connects the necessary previous blocks (also if more than 1), until the whole graph is finished, and it worked fine. More later.
AMG: What does this line do?
exec bash -c export LADSPA_PATH=/usr/lib64/ladspa/
To the best of my knowledge, this starts a bash process and tells it to set its LADSPA_PATH variable and put it in the list of variables to be exported to the environment of any child processes it starts. But it doesn't actually tell bash to start any child processes, so in the end nothing happens. If you wanted for this variable to be exported to Tcl's child processes, wouldn't you instead do the following?
set env(LADSPA_PATH) /usr/lib64/ladspa/
Mar 21 '13 TV Right, it doesn't do anything but remind me where to get my adapted jack-rack program (with coordinates in the command line) from, so I have either to do that via the env array (which I knew about), or, as I do it, by setting the environment variable in the bash/gnome shell, before I start the script !
See also Analyzing combined filter types with BWise graphs for Jack and for instance Creating arrays of wave formulas with BWise .