Elegance vs. performance
Richard Suchenwirth 2003-08-08: You can write an algorithm elegantly (i.e., in few lines of code, using few or no local variables, etc. - see the Zen of Tcl), or performantly (i.e., not wasteful in time or memory). Ideally, these two come together, but in reality, elegant algorithms may show bad performance.
Consider this elegant way of computing the sum of a list of numbers:
proc sum1 list {expr [join $list +]}and the more conventional way, which uses 2 local variables:
proc sum2 list {
set sum 0
foreach i $list {
set sum [expr {$sum+$i}]
}
set sum
}
#--- The only difference here is that the [expr] arguments are not braced:
proc sum3 list {
set sum 0
foreach i $list {set sum [expr $sum+$i]}
set sum
}AK: How about this sum4, (if we know that there are only integer numbers to sum)?
proc sum4 list {
set sum 0
foreach i $list {incr sum $i}
set sum
}Here is a little testframe to illustrate the respective performances, and draw them as curves on a canvas. It shows that sum1 (red) takes exponential time as lists grow longer, while sum2 (blue) remains pretty linear. sum3 (green) is initially worse than sum 1, but from the break-even point on it's better:
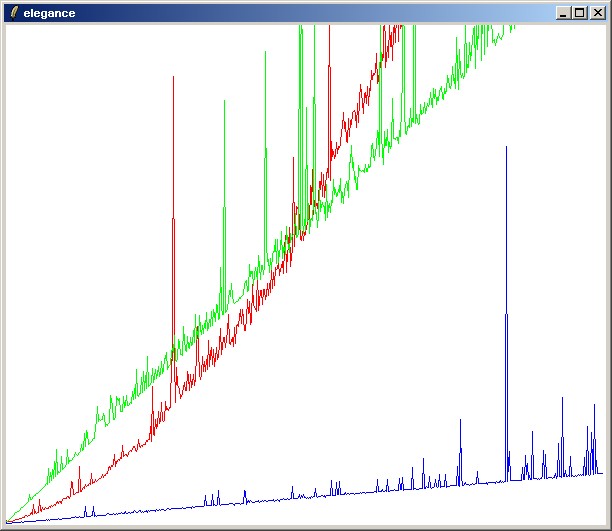
pack [canvas .c -bg white -width 600 -height 500] -expand 1
.c create line 0 500 0 500 -fill red -tag sum1
.c create line 0 500 0 500 -fill blue -tag sum2
for {set i 1} {$i<600} {incr i} {
set list [lrange [string repeat "1 " [expr {$i*2}]] 0 end]
set t1 [lindex [time {sum1 $list}] 0]
.c coords sum1 [concat [.c coords sum1] $i [expr {500-$t1/40}]]
set t2 [lindex [time {sum2 $list}] 0]
.c coords sum2 [concat [.c coords sum2] $i [expr {500-$t2/40}]]
update
}I was a bit surprised by the big difference. I will continue to start with elegant code, and tune it to performant when necessary, but deep in my heart I dream of a language that can performantly evaluate elegant expressions....
Anon: That language is J - the successor to APL. The code to add your list in J is:
+/ list
DKF: In Tcl 8.5 we'd just do:
tcl::mathop::+ {*}$listThat's significantly faster (~25%) than even sum4 on a list of a thousand elements.
SS: LISP seems the nearest today, there are compiled versions of CL and Scheme performing nearly half of native code speed. Also the SUN Self implementation was only 4/5 times slower then optimized C.
RS: In Lisp, it would go like this (tested on Emacs Lisp):
(defun sum0 (list) (eval (cons '+ list)))
[name redacted]: or like this (Common Lisp, LispWorks implementation):
(defun sum0 (list) (apply #'+ list))
RS: Emacs Lisp allows to do without the # (which denotes a function name):
(defun sum0 (list) (apply '+ list))
SS: In Scheme it looks like this:
(define (sum0 list) (apply + list))
HZe: I tried out this script and was (again) amazed how simple things can be done in TCL. Just for curiosity I changed sum3 to be identical to sum2. I expected to have the red and the green curve at about the same position..., but it was not. Can anyone explain?
DGP: Probably shared literals and bytecode compiling.
HZe: stupid me, I mixed up the colors. I changed sum3 (green), so that it is equal to sum2 (blue). The result is as I expected: blue and green are about the same. Red (elegance) is way off. Sorry...
I also changed the script a bit and added sum4:
proc sum1 list {expr [join $list +]}
proc sum2 list {
set sum 0
foreach i $list {
set sum [expr {$sum+$i}]
}
set sum
}
proc sum3 list {
set sum 0
foreach i $list {
set sum [expr {$sum+$i}]
}
set sum
}
proc sum4 list {
set sum 0
foreach i $list {incr sum $i}
set sum
}
pack [canvas .c -bg white -width 600 -height 500] -expand 1
array set color {
1 red
2 blue
3 green
4 yellow
}
foreach idx {1 2 3 4} {
.c create line 0 500 0 500 -fill $color($idx) -tag sum$idx
}
for {set i 1} {$i<600} {incr i} {
set list [lrange [string repeat "1 " [expr {$i*2}]] 0 end]
foreach idx {1 2 3 4} {
set t [lindex [time {sum$idx $list}] 0]
.c coords sum$idx [concat [.c coords sum$idx] $i [expr {500-$t/40}]]
}
update
}
CMCc: Why should sum be so much slower? It calls fewer functions, all of them written in C. This bears some investigation. Is it the join, or the expr parsing that's exponential in this? Or both?
Ok, a slight modification to the above program shows that the exponential component is the expr command. I wonder why expr is exponential in the number of terms?
I've set up a page exponential time to explore these questions.
I was wrong, dkf corrected me, it's actually quadratic time, so I've moved the discussion there.
NEM: offers this version which is (IMHO) elegant, and linear time (although still much slower than the other solutions). We use a fold function and a binary + operator to write the sum:
proc + {a b} { expr {$a + $b} }
proc foldl {func init list} {
foreach item $list {
set init [uplevel 1 [linsert $func end $item $init]]
}
return $init
}
interp alias {} sum5 {} foldl + 0Here's the graph (as before, but with purple showing the new result):

As you can see, the O(N) vs O(N^2) comes into effect to allow this version to win over the expr [join] version for large lists.
SS 2005-04-04: In Jim you can have both elegance and performance to solve this problem with:
+ {expand}$listThis works with zero length lists too because + without arguments returns the neutral 0.
AMG: Hooray, Tcl has this too! See {*} and Math Operators as Commands. Some of the more useful combinations:
+ {*}$list ;# Sum
* {*}$list ;# Product
& {*}$list ;# Bitwise and
| {*}$list ;# Bitwise inclusive or
^ {*}$list ;# Bitwise exclusive or
== {*}$list ;# Numeric quality
eq {*}$list ;# String equality
< {*}$list ;# Strict increasing order
<= {*}$list ;# Increasing order
> {*}$list ;# Strict decreasing order
>= {*}$list ;# Decreasing orderAM 2009-07-20: In a recent e-mail exchange between Andreas Kupries and myself the question arose whether a particular procedure in the math::statistics package of Tcllib could be simplified. The page Performance and simplification of code - implementing the basic statistics procedure discusses this.