Sumerian Construction Rates and eTCL Slot Calculator Demo Example
Sumerian Construction Rates and eTCL Slot Calculator Demo Example
This page is under development. Comments are welcome, but please load any comments in the comments section at the bottom of the page. Please include your wiki MONIKER and date in your comment with the same courtesy that I will give you. Aside from your courtesy, your wiki MONIKER and date as a signature and minimal good faith of any internet post are the rules of this TCL-WIKI. Its very hard to reply reasonably without some background of the correspondent on his WIKI bio page. Thanks, gold 12Dec2018
- Sumerian Construction Rates and eTCL Slot Calculator Demo Example
- Introduction
- Section A, Canals and Canal Regulators as construction projects
- Section B, the Gades brick piles, major construction during reign of King Amar-Sin, many assumptions
- Section C, Gathering Test Cases
- Pseudocode and Equations using coefficients
- Table 1, Sumerian coefficients for Canal Excavation rates
- Table 2, Sumerian Canal Regulators, known
- Table 3, Sumerian and Akkadian Canal Terms
- Table 4, Sumerian coefficients for daily work rate, supplements etc
- Table 5. , Sumerian Canal hierarchy and possible transit ships
- Table 6. , Schedule for Gaes bricks, tentative and many assumptions
- Table 7. , Brick Inscription, possibly from Year 3 or 4 of Amar-Suen
- Testcases Section
- ScreenShots Section:
- References:
- Appendix Code
- Comments Section
Introduction
gold Here is some eTCL starter code for calculating materials and dimensions of ancient Sumerian buildings. The impetus for these calculations was checking reed and mud brick construction in some excavation reports and modern replicas. Most of the testcases involve replicas or models, using assumptions and rules of thumb.
In the Sumerian coefficient lists on clay tablets, there are coefficients which were used in determining the amount of construction materials and the daily work rates of the construction workers. In most cases, the math problem is how the coefficient was used in estimating materials and work rates. One difficulty is determining the effective power of the coefficient in base 60. For example, 20 could represent either 20*3600,20,20/60, 20/3600, or even 1/20. The basic mud wall dimensions and final tallies were presented in the Sumerian accounts on clay tablets, but the calculations were left off the tablet. At least one approach for the modern reader and using modern terminology is to develop the implied algebraic equations from the Sumerian numbers. Then the eTCL calculator can be run over a number of testcases to validate the algebraic equations.
Section A, Canals and Canal Regulators as construction projects
In Sumer of the Ur III dynasty, there were canal regulators at Girsu, Lagash (2), Umma, Larsa,Kilmah, Shurruppak, Isin, and elsewhere. The canal regulators were used to channel water into the canal bed, moderate the channel stream level, and divide offshoot canals into several streams for irrigation. Usually at the site of a major regulator along a navigable canal, there was a rest house and kitchen for transferring travelers and canal workers, as well as a military depot to defend the installation. From the remains of the Amar-Suen canal and voyager logs, there were Rest Houses along the Amar-Suen canal about 10 to 20 km apart. The Umma texts suggested that canal boats were available at Umma of 5-60 gur capacity, equivalent to modern cargo ratings of 0.35 to 18 cubic meters. From the remains and excavations at Girsu, the sluice of the canal regulator was 11.4 meters long and 3 meters wide.
From remaining extant walls of the Girsu canal regulator, the sluice was about 5 meters depth. The canal downstream was about 16 meters wide (in ancient times). The immediate area was has been dry in modern times. At least in modern thinking, the difference between the Girsu sluice width (3 m.) and the canal width (16 m.) would preclude efficient operation of the regulator. At Lagash, the sluice of the canal regulator was 3 meters wide and 18 meters long. The Lagash canal regulator has reinforced brick fans to channel the ancient canal flow, of 24 and 27 meters length respectively (on the sides of the regulator). The Lagash canal downstream from the regulator was about 6 meters wide (in ancient times). The immediate area was has been dry in modern times. The Kimah agricultural regulator was 6 meters wide and was led into 4 channels for agriculture. Possibly the smaller channels of Kimah were 6/4 or 1.5 meters wide. At least, irrigation canals of 1.5 meters width would be compatible with the smaller irrigation canals with square cross sections (1.5 m. sides) mentioned in the math texts. From the Girsu remains, coefficient lists, and math problems, the depth of a regulator sluice was usually 5 meters (rounded).
In the coefficient lists and math problem texts, there are canals and canal regulators discussed with some dimensions, although no one to one correspondence can be concluded. The math constant IGI.GUB sa3 ID2 he-ri-im (constant of the width of an excavated river ) was 30/60 ninda in s. notation or about (30/60)*6, 3 meters. The math coefficient IGI.GUB sa3 PA5.SIG (constant of a small canal, side or depth) was 48/60 ninda in s. notation or about (48/60)*6, 4.8 meters depth. There were math problems listed for small canals of length/width/depth of 1800/1.5/1.5 meters and other problems for small feeder canals of 1800/0.5/0.5 meters. There was a corrupted math problem about a canal regulator ( Akk. tarahhu) with possible length of 1800? meters and possible canal upper width of 10? meters. Generically, the width of a regulator sluice was usually 3-6 meters, the width of the main canal was 6-16 meters, the width of small square irrigation canals was 1.5 meters, and the smallest square canals mentioned were 0.5 meters (from the math problems).
The scale or order of magnitude of the Lagash regulator can be estimated from the Lagash inscriptions and Sumerian coefficients. The boulder indicated 648,000 fired bricks and 1840 gurs of bitumen. Gurs are volumes of 0.3 cubic meters, so one can start with volume computations. Since the larger Sumerian canal ships were rated at 60 gurs, the number of shiploads could have been 1840 gurs/60, 30.66, or rounded 31 ships. In modern units, the volume of bitumen used was 1840*.3 or 550 cubic meters. The typical fired brick of the 2/3 cubit type was length/width/depth was 0.33/0.33/0.08 meters. From the average density of fired brick at 2000 kg/c. meters, the total mass of the bricks was 6.48E5*0.33*0.33*0.08*2000 or 1.129E7 kilograms. Since bitumen is about the density of water(1000 kg/c.m.), the 60 gur capacity of a Sumerian ship would be equal to a cargo of 60*.3*1000.,18000, or 1.8E4 kilograms. Converting into shiploads of brick, the project would be equivalent to 1.129E7 / 1.8E4 ,0.6272E3, or rounding 627 shiploads of brick. From the British clamp kilns of the 1880's, a British clamp kiln would need 1135 kg wood for 3800 kilograms of green clay for soft fired bricks. Using similar proportions, the Sumerians would need 1135*1.8E4/3800 or 5.376E4 kilograms of wood or reeds. Using the Sumerian coefficients, some limits on the workdays needed to make the bricks is possible. As a first cut, the number of workdays would be 648,000/240 or 2700 workdays for making brick.
It is very difficult to get a handle on the numbers of workers and duration of the project. The population of Lagash about 2300 BCE is estimated to be from 10,000 to 30,000 inhabitants. On a seasonal basis, team of workers could be brought off the farmland, and probably Lagash had a pool of skilled workers that was about 1/4 the population. King Enmetena of Lagash reigned from 2404-2375 BCE. Although are no explicit texts on the duration of the canal building, the building or restoration of the canal probably took place between 2004 and 2000 BCE, a period of four years. There are a lot of iffy's here. If all the bricks were made in a single "month of making bricks", then the needed brickmakers would be 2700/30 or 90 brickmakers . If the project was spread over 5 years, then estimated workdays making bricks would be 2700/5 or 540 workdays per year. If on a one month assignment during the "month of making bricks" (over extended 5 years, the required brickmakers would be 540/30 or 18 brickmakers. After the crops were planted, perhaps 2500 workmen would be available for digging, porting clay, and collecting reeds (for building material and fuel) for a period of 60 days. The ratio of about one foreman for 40 workmen gives 2500/40 or rounded, 60 foremen.
Some commodity price records are known for various eras in Sumerian accounts, Babylonian astronomer tablets, and partly in the coefficient lists. One piece of silver bought 288 bricks. If bought separately, the bricks on the project would cost 648,000/288 or 2250 silver pieces. One piece of silver bought (2/5) gur of bitumen, so the bitumen would cost 1840/(2/5) or 4600 silver pieces. Craftsmen were normally paid 1 ban or 10 liters of grain. The craftsman and other wages can be calculated in terms of silver. One silver piece bought a gur or 6 ban of grain. In terms of accounting, a craftsman could be paid in 1 ban of grain, 10 liters of grain, 1/6 gur of grain, or 1/6 silver piece. Generally, workmen, field labor, or hirelings were paid on the books in 2 bowls or 1 liters of grain, 1/5 ban of grain, 1/30 gur of grain, or 1/30 silver piece. On the books, the foreman would be paid 5 ban, 50 liters of grain, 5/6 gur of grain, and 5/6 silver piece. From some accounts, the foreman was responsible was responsible for accounting for the labor, and for arranging distribution of grain to the higher status workers, and for furnishing bowls of gruel or hot mutton soup to the lower status workers. The labor of 2500 workmen for two months would cost 2500*30*2*(1/30) or 5000 silver pieces. However, traditionally about 1/10 workmen labor or more was taxed to the King. So probably only the brickmakers and foremen received a salary. In fact, the boulder inscription could imply forced or unpaid labor.
With the possible exception of fan walls to channel water into the sluice, the bulk of the regulator was underground and probably can be considered an excavation, at first. From the coefficient lists and the average excavation rate, the workdays of excavation would be roughly 6.48E5*0.33*0.33*0.8/3, 1882 workdays. The workdays of digging mud for bricks would be roughly 6.48E5*0.33*0.33*0.8/3, 1882 workdays. The task of gathering sufficient reeds and firewood would be 5.376E4 kilograms of wood/250, or 179 workdays. 2700 workdays for making brick was previously figured. Though no coefficients, laying a reed mat foundation might be 500 workdays. The workdays of laying brick would be roughly 6.48E5*0.33*0.33*0.8/3, 1882 workdays. The workdays of plastering the completed brick surface would be 700 workdays. Suggest that making the wooden gates might be another 500 workdays. So far the total is 9705 workdays. With 90 brickmakers and assistance of the 500 workmen, the project would take about 9705/90 or 108 days. The remaining 2000 workmen would clearing and digging the extended canal. If materials and labor are accounted, the price of the Lagash regulator and canal improvements might be 2250 bricks + 4600 (bitumen) + 5000 (labor workmen) + 1620(brickmakers/craftsmen) + 4500 (foremen), as 18000 silver pieces.
Section B, the Gades brick piles, major construction during reign of King Amar-Sin, many assumptions
A major construction project in the reign of Amar-Suen was the building of the en-priestess residence at Gaes harbor in the city of Ur, as partly tallied in tablet AO7997. The tablet AO7997 describes a number of brick piles which included volumes of 9.66 sar for baked bricks. While not all the mentioned AO7997 bricks are overtly baked, the volumes are staggered by roughly 3 sar each and equivalent to 17.5, 37, 56.4, and 74.9 cubic meters. The brick piles seem to show some bricks in a drying layout of 2 cubits height. Then the same volumes are shown with the height doubled, and now the height and width form a square cross section (4x4 cubits). The length remained the same. The later Sumerian square cross sections would not be good for drying bricks, but might be useful for retaining fuel generated heat, like the square cross section of the British clamp kiln. Although not the same units, the largest Sumerian pile of baked bricks has a 6:1 ratio for L/W, from LWH 24/4/4 cubits. The British clamp kiln has a ratio of 5.46:1 for L/W, from LWH 18.29/3.35/3.65 meters. Could some of these piles (sig4 anse) be the equivalent of field drying, trench, or clamp kilns for baked bricks? It would seem convenient to stack green bricks one time in a trench as a preliminary base. Then after the first bricks have dried in a 2 cubit high layer, place extra fuel, 2 cubits more extra height, and overlapping bricks between the rows. No fancy arches needed here, since the Sumerian bricks are 0.33 to 0.5 meters across, wider than modern bricks and can overlap or corbel a fairly wide tunnel for fuel and air. A layer of dirt and debris on the sides and roof would add insulation to the structure, as the center burned. The volume of the mud kiln was about 1/4 of the 1880’s clamp kiln and probably was counted as a standard or integer fraction of standard brick kilns. From the British authors, the length of the clamp kiln was more specific to the site, dependent on the need of bricks locally and at a building site.
Some peg points on the Gaes constructions or restoration can be established. A school text can give proportions on the workdays for mudbrick construction. The school text reported 84 workdays for 5760 unfired bricks in initial site preparation. In round numbers, the Gaes restoration used 62000 bricks, some fired. Using proportions of the school text, the Gaes site preparations took 62000*84/5760, rounding 904 workdays. Based on the coefficients, another estimate was 9705*62000/648000 or 928 workdays. From the text on the bricks, there appear to have been 9 overseers. In UrIII, overseers or foremen usually commanded a range of 20 to 40 workers, typically 30 workers. At a minimum, there would have been 9*30 or 270 workers in 9 workcrews. There are credit tablet for 270 workers, possibly at Gaes, paid by Lu-Shar, mayor of Umma. The available texts give estimates of the brick numbers involved and imply brick preparations at Gaes, but not details of the actual Gaes construction. The understanding is that sun fired bricks would take a year or hot summer to cure. The best estimate is that the Gaes project was staggered over several years to cure the bricks and assure labor after the spring planting.
In some Sumerian contexts, the Giparu or sacred precinct was the residence of the en-priestess of the Moon god (Nanna or Ninnar), effectively a state cult for enthroning the king. The Giparu was the site of the Sacred Marriage Rite, probably conducted every year at various major cities. "pa4" is a Sumerian root word meaning priest; "gi6" is a Sumerian root word meaning earth or dark place. Sometimes, the en-priestess was the daughter or other kin of the king. In Sumerian, "en" means the king or shepherd. Also, successive en-priestesses or other offerings were buried under the floor of the Giparu. A later era calcite medallion of Enheduanna shows the Akkadian en-priestess conducting a threshold sacrifice. The medallion shows a triangular wall of 15 degrees face which would be called a buttress wall in modern terms, heavy construction by any standards.
The brick piles at Gaes can be placed in a tentative association with the events in the reign of King Amar-Suen. The associations are not really a formal history, but are culled from clay tablets on receipts, chits, and legal documents from the Ur III period. King Amar-suen came to the throne in 2046 BCE and the reign numbers refer to this date. The following individuals received a staff of high office:Akhuni, Ue-Enlilla son of the Elamite(?), Lu-Shara son of Urzu, Lu-ibgal son of Lugal-massu, the military governor, and Ur-Lisi, the governor of Umma province (no dates given). One tablet cites Lu-Shara as a scribe and another tablet as a hazannu official (mayor ). Lu-Shara was probably the mayor or administrative scribe under Ur-Lisi, in the reign of Amar-Suen. In Amar-Suen 1, Ur-Shara the scribe paid a credit for 19 copper sickles and 8 copper pickaxes. In Amar-Suen 1, the governor of Umma paid a credit for 170 male workers or about 5 workcrews for one day. Three promissory notes and two receipts on the Gades bricks were dated to the month of Akiti of Amar-Suen 4, mostly similar descriptions of the brick piles. Lu-sin accepts 33 sar of brick for the (moon?) temple and 10 sar of bricks for the military depot (marsa) storage house (no dates or specific location given). By custom, the buttressed walls of the en-priestess residence were exceptionally thick and the foundation under the walls was extra strong. While not all the bricks can be established as fired, the fired bricks were probably intended as foundation bricks, underground dedication shrine boxes ,and high use floors/thresholds (ref. the Nimintabba temple at Ur and the Inanna temple at Nippur. The fired bricks and extra strong foundations are believed due to the custom of interring the En-priestess and sacrifices under the floor of the temple. Some of the fired bricks were probably used in rebuilding the Karzida quay in front of the moon temple. In Amar Suen 7, The en-priestess En-Nanna-Amar-Sin-kiagra was installed at Gades/Karzida (for the first time). In Amar Suen 9, the en-priestess En-Nanna-Amar-Sin-kiagra was installed at Gades/Karzida (third time). The project was believed to be completed in the ninth and last year of the reign of Amar-Suen. The available data suggests the building or restoration on the moon temple was completed in 4 to 6 years.
Section C, Gathering Test Cases
In planning any software, it is advisable to gather a number of testcases to check the results of the program.With back of envelope calculations, a number of peg points were developed to check output of program. The math for the calculations were confirmed by pasting statements in the TCL console. Also, some of the pseudocode statements were checked in the google search engine which will take math expressions. Aside from the TCL calculator display, when one presses the report button on the calculator, one can develop a more detailed report.
Using the eTCL calculator, a single brick wall of L/W/T 27/2/0.66 meters can be estimated. On the eTCL calculator, set the temple width to zero and the thickness to half the wall. The eTCL calculator (27/0/2/.33) gives 35.64 cubic meters. For comparison, hand calculations give L/W/T , 27*2*.66 or 35.64 cubic meters. A square brick column or rubble filled wall can be figured with a similar scheme. One can also use the eTCL calculator for a rectangular construction of 4 walls and subtract a wall or doorway of known dimensions.
The eTCL calculator made some order of magnitude calculations for a trial Sumerian house with some assumptions. The Orchard House was 30.11 meters long, 11.5 meters wide, and walls 3 meters high with a surface area of 30.11*11.5, or 346.6 square meters. As constructed, the front wall was 10.45 meters and back wall was 11.5 meters, presumably the difference of (11.5-10.45) or 1 meter was the threshold or entrance. One side of the house was extended as a garden wall. For the Orchard House, the ratio of wall length to width was 30.33/11.5 , 2.618:1, or rounding 3:1. For an initial cut of the wall volume using hand calculation, the total wall volume would be the sum of the front wall L*H*T (11.5*3*0.33), the rear wall(11.5*3*0.33), side wall (30.11*3*0.33), and second side wall (30.11*3*0.33). The eTCL calculator makes the assumption that all bricks are of the "2/3 cubit" burned brick type. The garden wall would enclose 60*60 sq. meters or 4*60 perimeter of square iku, based on modern assumptions. Using an assumption that the wall thickness of the Orchard House was 0.33 meters, the eTCL calculated a wall volume of 77.7 cubic meters. If the "2/3 cubit" burned brick was used, the total number was 8924 bricks. The estimated workforce was 2 foremen (salary of 50 liters), one junior scribe (10 liters), 56 craftsmen (10 liters), and 16 subsistence men (0.5 liter). While the number of bricks has not observed on any receipt, the estimated workdays for making bricks would be 8924/240 or 37.2 workdays, within the nominal workforce for one day. The estimated workdays for digging clay for bricks would be 77.7/3 or 25.9 workdays, within the nominal workforce for one day. Presumably, the bulk of the bricks were made on site, but the available text doesn't state so. For comparison, the average Sumerian mudbrick house was about 90 sq. meters, and the average room size was 3 meters width by 3.65 meters length,3* 3.65, or about 10.95 square meters (from several excavations). The coefficient 20 E2 DU3.A (house build work in base 60) was 20/60 sar or 10.6 sqm, the size of a room or poor family home apartment. The Sumerian mudbrick houses generally contained rooms of 11 square meters built around a central courtyard. For the Orchard House, the general guidelines suggest about 6 rooms (3*3.6 m.) on both sides of a central courtyard about 5 meters wide.
For a more substantial project with the eTCL calculator, consider building or repairing an orchard wall of 306 rods or 3672 meters. Such a mudbrick wall would be L/W/H 3672/0.5/1.5 with sun dried bricks of the one cubit sides, 0.5*0.5*.0.08 meters. The volume of the mudbrick wall would be 3672*0.5*1.5 or 2754 sq meters (by hand calc). Setting for single wall, the eTCL calculator setting (3672/0/1.5/.25) calculates a volume of 2754 sq. meters. The eTCL calculator does not use the sun dried bricks, but the number of bricks should be wall volume over brick volume, 2754 over (0.5*0.5*.08) or 1.377E5 sun dried bricks. Using the coefficient lists, the estimated mandays digging clay for the bricks would be wall volume 2754/3 or 918 mandays. The task of making bricks would be 1.377E5/240 or 573.75 mandays. For a tentative budget on the orchard wall, the sum of 189*0.5(subsistence men)+378*10 (craftsmen) + 2*10(junior scribes)+10*50 (foremen) would cost 4394 liters of grain.
According to model document, the temple of Sara at Umma had overall length of the temple was 202 cubits (101 meters), width 6 cubits (3m), and height 13 cubits (6.5 m). The thickness of the walls were not given. The temple building contained 18.33 sar of baked bricks and 18.5 sar of sun dried bricks.The fraction of sundried over baked was 18.5/18.33, 1.009, or roughly 1. The total of fired and sun dried bricks was (18.33 +18.5)*720 or 26518 bricks. The text implies that the baked bricks were laid on the outside and the unbaked bricks formed the interior. If the baked bricks were the L/W/T 0.33/.33/.08 meters and unbaked bricks were laid as a side by side course with larger fired brick (.66/.66/.08?) corbels, then the thickness of the wall might be between 0.66 and 1 meter thick. Gaming with the eTCL calculator suggested the wall thickness might be 0.87 meters, with a total wall volume of 237.5 cubic meters. Using the daily task of stacking bricks as 1.13 c.m., the workdays stacking bricks was 237.5/1.13, rounding 210 workdays.
According to model document, the temple of Ninurra at Umma (UrIII) had overall length of the temple was 148 cubits ( 73.6 meters), the width was 6 cubits (3m), and height of 22 cubits (11m). The thickness of the walls were not given. The temple building walkway or causeway contained 1 ese of bricks or 576 sar. The causeway number was suspiciously high, but suggest a fraction of the causeway or fill bricks in the tallies may make troubles for the simple calculator algorithm. The temple building contained 35 sar of baked bricks and 16.5 sar of sun dried bricks. The fraction of sundried over baked was 16.5/35, 0.471, or roughly 1/2. The total of fired and sun dried bricks was (35+16.5)*720 or 37080 bricks. The text implies that the baked bricks were laid on the outside and the unbaked bricks formed the interior. If the baked bricks were the L/W/T 0.33/.33/.08 meters and unbaked bricks were laid as a side by side course with larger fired brick (.66/.66/.08?) corbels, then the thickness of the wall might be between 0.66 and 1 meter thick. Gaming with the eTCL calculator suggested the wall thickness might be 0.87 meters, with a total wall volume of 1466 cubic meters. Using the daily task of stacking bricks as 1.13 c.m., the workdays stacking bricks was 1466/1.13, rounding 1297 workdays. For the temple of Ninurra, the fraction of unbaked over baked bricks was 1/2, substantially different than the temple of Sara at 1.
For the testcases, one would like to get realistic testcases from the ancient sources. The gist of a model document or scribal copy exercise (2300 BCE.) formulates the wall and foundations of the two temples of Sara and Ninurra at the city of Umma of Ur III. The model document gives some dimensions and numbers of bricks in Sumerian units. Other cuneiform documents from various eras give estimates for manhours for tasks like canal digging and hoeing weeds, as foremen tally the labor and supplies for the accountants. The eTCL calculator or similar modeling calculations can give some idea of the scale of the Sumerian public works. Aside from the large temples, the Sumerian canal regulators and canals are of historical interest. In the modern era, ship canals and water irrigation systems are still being planned at great expense. So it is worthwhile to compare the modern canal solutions and fees with the Sumerian solution.
Pseudocode and Equations using coefficients
| Pseudocode with some Equations | |
|---|---|
| namespace path {::tcl::mathop ::tcl::mathfunc} | |
| pseudocode: mortar = vol of walls times 1/6 , 144. c.m.* (1/6) or 24 c.m. | |
| pseudocode: brick volume = 0.33*.33*.08, or 0.0087 cubic meters | |
| pseudocode: answer is mandays of labor or silver pieces +- error | |
| workdays on foundation = vol of foundation / coefficient | |
| = 36 / 3 or 12 workdays | |
| workdays making bricks = number of bricks / coefficient1 | |
| = 1.65E4 / 240 or 69 workdays | |
| workdays digging clay = vol of walls / coefficient2 | |
| = 144. c.m. / 3 c.m. or 48 workdays | |
| workdays porting clay = vol of walls / coefficient3 | |
| = 144. c.m. / 4 c.m. or 36 workdays | |
| workdays mixing clay = vol of walls / coefficient4 | |
| = 144. c.m. / 3 c.m. or 48 workdays | |
| workdays making bricks = number of bricks / coefficient5 | |
| = 1.65E4 / 240 or 69 workdays | |
| workdays laying bricks = vol of walls / coefficient6 | |
| = 144. c.m. / 3 or 48 workdays | |
| workdays making 3 doors = 3 doors * coefficient7 | |
| = 3 doors / (2/3) or 4.5 workdays | |
| workdays making reed thatch = roof area /coefficient8 | |
| = 5*10 sq.m. / 1.125 or 44.4 workdays | |
| workman wages = total workdays times 1/30 silver piece | |
| mass of bricks times 1/6 = mass of mortar | |
| mass of bricks + mass of motor = amount of clay needed. | |
| length wall of bricks times 1/5 = extension or footing of foundation | |
| dimension of bricks times density of clay = mass of clay | |
| 454 kilograms coal over 1000*3.8 kilograms of clay, 454/3800 | |
| 1135 kg wood for 3800 kg of clay | |
| 32001 kg wood for 107160 kg of clay. | |
| 2001 kg wood./ 600 = 53.5 workdays of firewood collection | |
| workman wages = total workdays times 2 liters of grain |
Table 1, Sumerian coefficients for Canal Excavation rates
| canal excavation | coefficient in sars per man*workday | daily workload cubic meters | rated depth cubits | Sumerian tablet. 1 | Akkadian? tablet. 2 | comment |
|---|---|---|---|---|---|---|
| first level | 20/60 | 6 | ground level,1-2 cubits,0.5-1.0 meter | silutum | il-lum | first level is easiest, (20/60)*18= removing 6 c. meters from canal |
| second level | 10/60 | 3 | 2-3 cubits,1-1.5 meters | dusu | obscured | dusu is construction basket or yoke-of-2-buckets, (10/60)*18= lifting 3 c. meters from canal |
| third level | 6/60+40/3600 | 2.0 | 3-5 cubits, beyond 5 cubits,1.5-2.5meters,beyond 5 meters | dusu | had/talum ihd/til | dusu is construction basket or yoke-of-2-buckets , (400/3600)*18= removing 2 c. meters from canal |
| These rates are primarily from math problems, but are partially included in some Sumerian Coefficient Lists | Also, third level reported with other values, eg 8+30/3600 |
Table 2, Sumerian Canal Regulators, known
| location of canal regulator | canal and modern river, if known | est. number of bricks | est barrels of bitumin | Est. arable hectares | year before common era | comment |
|---|---|---|---|---|---|---|
| Isin. | Isin canal and Euphrates river | 1.3E6 bricks. | 7971 | 2700??? | 1881 BCE | King Sumuel of Larsa |
| Girsu | Id-Nina-Gina canal and east branch Euphrates river | 68.6E3 bricks | 420 | 10E4 ha | 2150 | King Gudea, ref foundation cones |
| Kimah | Id-Nina-Gina canal and east branch Euphrates river | bricks | 2E4 ha | 2150? | King Gudea? | |
| Umma | Iturungal canal and east Euphrates delta | 1.55E4 ha | ||||
| Lagash First | Lumagimdu canal | 6.48E5 bricks | 1840 | 27200 | 2400??? | King Enmetena of Lagash, ref dedication boulder |
| Lagash Second | Lumagimdu canal | 4.32E5 bricks | 1840 | 27200 | 2350 | King Uru-inimgina of Lagash |
| Note, Several kings claimed authorship of the same canal or restored the same canal, so attribution is tricky. |
Table 3, Sumerian and Akkadian Canal Terms
| adug | irrigate with canal water | literally < water pot< , Akk. saqu sa eqli |
| aigidu | canal water | literally < <i see water<, Akk. sekiru |
| bala-ak | reposition boat over canal (weir?) | listed on voyage records, literally <unload crossing<, Akk. nabalkutu or nabalkat |
| bur | canal depth | ref math problems, Akk. buru |
| dagal-an-ta | upper canal width, width at top | ref math problems, literally < side large upper > |
| dagal-ki-ta | lower canal width, width at bottom | ref math problems, literally < side large earth > |
| durum.tus.tus | regulator type, another word | literally <wet small small< |
| dusu | third level of canal | ref coefficient lists and math problems, literally <basket<, Akk. tupsikku |
| egir | second wooden wall | egir or egar means wall, Akk. igaru , literally <from the earth< |
| ges kes.du | regulator | literally <wood bind built <, kes means gather, bind |
| gugal | canal inspector | literally < great man or foremost man< , Akk. gugallu |
| hirim | (general) ditch | Akk. mitru |
| id | (general) river | Akk. naru |
| id he-ri-im | river canal path | cited coefficient lists, literally < river path high mud <, Akk.naru or mitru |
| igi | first wooden wall | igi means watcher or (i see) |
| iku | field, area unit | field surrounded by irrigation ditch, 60*60 sq meters, Akk. iku (sic) |
| ka-i7-dat | lift canal boat bow into different (or higher?) channel | ref voyage records, literally < open mouth support >, Akk. nabalkutu or nabalkat |
| kab-kud | divisors breaking into smaller streams | literally <measure cut < |
| kun | outlet | literally < animal tail< Akk. zibbatu |
| kun.zi.da | regulator type, another word | ref voyage records, literally <outlet cut side drain< |
| mehru | M.B. (general) weir | ref Middle Babylonian |
| mitru | (general) canal or watercourse | Akk. mitru |
| na | river level, canal level | units of level change, equal to 4 susi, records of Babylonian Astronomers |
| nari | canal | Akk. naru |
| nag-kud | narrow basin or reservoir near canals | possible agricultural basins for watering vegetables and herds, literally < drink cut<, Akk. butuqtu |
| natbaktu | M.B. canal regulator | ref Middle Babylonian |
| pa | (general) small canal, ditch | Akk. palgu |
| par | small canal, ditch | Akk. palgu |
| pa.sig | small canal, ditch | literally < little canal<, ref coefficient lists Akk. palgu |
| pa.sig.libir.ra | old small canal, ditch | ref math problems. literally < old little canal<, Akk. palgu |
| pi natbakti | M.B. first gate of canal regulator | ref Middle Babylonian |
| silitum | first level of canal | ref math problems, silum meant depression or concavity , Akk. silu |
| sepit natbakti | M.B. second gate of canal regulator | ref Middle Babylonian |
| sur | small canal, ditch, foundation drain | Akk. suru |
| ta.ra.ah.hi.im.mi | regulator type, another word | literally <cut stream mudwall< |
| talum til? | second level of canal | ref math problems, til means broaden, expansion |
| tarkullatum | removable wooden beams | literally < cut stream < , epic of Gilgamesh |
| tarkulli | removable wooden beams | literally <cut stream <, epic of Gilgamesh |
| tarkullum | removable wooden beams | literally < cut stream <, epic of Gilgamesh |
| tul | water cistern | ref math problems, Akk. burtu |
| u-tir | water bridge? | literally <forest bridge< |
| us | canal length | ref math problems, literally <measure< |
| zubi | (general) canal or watercourse | Akk. mitirtu |
| Table includes compound words and phrases in Sumerian or Akkadian. | ||
| These are technical (math) terms which may not be found in dictionaries of single root words and | ||
| conventional literature. | ||
| Table includes cuneiform words of rare citation or even one single instance on a clay tablet, | ||
| which increases the uncertaincy of meaning. |
Table 4, Sumerian coefficients for daily work rate, supplements etc
| Sumerian coefficients for daily work rate, etc | |||||
|---|---|---|---|---|---|
| daily work of one man etc in base 60 | transliterated name | english | decimal /fraction | reciprocal | comment |
| 12 | u4, u4-1-se | hours of workday | 12 | 1/12 | 12 hours, common to several accounts and math problems |
| 3:45 | sa pi-ti-iq-ti | coefficient wall high manlife | 3/60+45/3600 | 16 | raising mud wall, 3/60+45/3600 surface a day |
| 30 | IGI.GUB sa3 ID2 he-ri-im | constant of the width of an excavated river | 30/60 | 2 | literally ( river, plenty, pour out, mud ), 30/60 ninda conv. to 3 meters width |
| 48 | IGI.GUB sa3 PA5.SIG | coefficient small canal side depth | 48/60 | 60/48 | literally ( canal side depth), 48/60 ninda conv. to 4.8 meters depth |
| 7:30 | i-za-ab-bi-il | coefficient canal labor | 7/60 + 30/3600 | 3600/450 | ( 450/3600) vol.sar. conv. to 2.25 cubic meters |
| 48 | a. sa3 | coefficient water of field | 48/60 | 60/48 | possibly daily rate for dipping water on field, 48/60 volume sar, conv to14.4 c. meters |
| 48 | igigub sig2 hi.a | coefficient wool | 48/60 | 60/48 | possibly daily rate of loom, conv to (48/60)*6, 4.8 meters length |
| 40 | igigub sig2 hi.a | coefficient wool | 40/60 | 60/40 | possibly daily rate of loom, conv to (40/60)*6, 4.0 meters length of spun wool |
| 18 | im-la | coefficient cone? | 18/60 | 60/18 | ref grain heap problems, Sum. imla, Akk. imlum |
Table 5. , Sumerian Canal hierarchy and possible transit ships
| Canal hierarchy and possible ships | printed in | tcl wiki format | ||
|---|---|---|---|---|
| canal/regulator | width meters | meters depth est. | info & possible ship | |
| Lagash regulator sluice | 3. | 5. | ref length 18. meters, arch. report, ma60gur | |
| Girsu regulator sluice | 3. | 5. | ref length 22.4 meters, arch. report, ma60gur | |
| Girsu main canal (downstream) | 16. | 5.? | arch. report, ma60gur | |
| excavated river, he-ri-im | 3 | 5? | coefficient tables, ma60gur | |
| Kimah agricultural regulator | 6 | 5? | arch. report, ma60gur? | |
| Kimah agricultural divisor streams | 1.5? | 1.5? | arch. report, ma10gur? | |
| small canal , pa5-sig | 3 | 5.? | coefficient tables, ref length 1800. meters, ma10gur? | |
| small feeder canal, pa5 | 1.5 | 1.5 | math problems, ref length 1800. meters, ma10gur? | |
| little old (silted) ditch, pa5-sig-libir-ra | 1. | 1. | math problems, ref length 30. meters | |
| smallest feeder ditch, pa5 | 0.5 | 0.5 | math problems, ref length 30. meters |
A reference length, width, and depth for a canal or ditch is defined as the most common or most cited in the cuneiform references, coefficient lists, and math problems, not exclusive of alternate values.
Table 6. , Schedule for Gaes bricks, tentative and many assumptions
| event | year of reign | year BCE | comment |
|---|---|---|---|
| King Amar-suen begins reign in third dynasty of Ur | Amar suen 1 | 2046 | clay tablet, king list |
| King Amar-suen directs restoring temples of Sumeria at Ur, Eridu, and Gades | Amar suen 1 | 2046 | building inscriptions & assumptions |
| Ur-Shara buys 19 copper sickles and 8 pickaxes | Amar-Suen 1 | . 2045 | food and economic preparations |
| Year King Amar-Suen raided Urbilum | Amar-Suen 2 | . 2045 |
| Year King Amar-Sin made a silver throne for Enlil | Amar-Sin 3 | 2043 | |
| bricks ordered?? | Amar suen 3?? | 2043 | assumption |
| bricks on site at Umma | Amar suen 4 | 2042 | 5 clay tablets |
| Lu-Shara pays credit for 270 workers at Gaes | Amar suen 4 | 2042 | clay tablet |
| Umma province ships bricks to Gaes, remaining mudbricks cured , building and repairing enpriestess residence (temple) begins at Gaes >> | Amar suen 5? | 2041 | many assumptions |
| Year Shashrum was raided for the second time | Amar suen 6? | 2040 | clay tablet |
| enpriestess En-Nanna-Amar-Sin-kiagra installed at Eridu (first time) | Amar suen 7 | 2040 | clay tablet |
| Year Khukhnuri was raided | Amar-Sin 7 | 2040. | clay tablet |
| enpriestess En-Nanna-Amar-Sin-kiagra installed at Eridu | Amar suen 8? | 2039 | clay tablet |
| Year the priest of Eridu was installed | Amar-Sin 8. | 2039 | clay tablet |
| possible project completed at Gades/Karzida | Amar suen 9? | 2038 | many assumptions |
| enpriestess En-Nanna-Amar-Sin-kiagra installed at Gaes/Karzida (third time) | Amar suen 9? | 2038 | clay tablet |
| King Amar-suen dies, trampled by hooves of oxen in battle??? | Amar suen 9 | 2038 | clay tablet, king list |
Table 7. , Brick Inscription, possibly from Year 3 or 4 of Amar-Suen
| Brick | Brick Inscription | possible year 3 or 4 of Amar-Suen |
|---|---|---|
| line No. | trans. | english |
| 1. | {d}amar-{d}suen | divinity Amar-Suen |
| 2. | nibru{ki}-a | chosen of heaven |
| 3. | {d}en-lil2-le | by the divinity Enhil |
| 4. | mu pa3-da | year of (the king is) a strong supporter (pole) |
| 5. | sag#-us2# | (year after the year) |
| 6. | e2# {d}en-lil2-ka | for the home (temple) of divinity Enhil |
| 7. | lugal# kal#-ga | powerful king |
| 8. | lugal# uri5{ki}-ma | king of urim |
| 9. | lugal# an ub#-da# limmu2-ba# | king of the four quarters |
Note: articles in parens are added for modern reading sense, since terms are written on a tablet line basis.
Testcases Section
In planning any software, it is advisable to gather a number of testcases to check the results of the program. The math for the testcases can be checked by pasting statements in the TCL console. Aside from the TCL calculator display, when one presses the report button on the calculator, one will have console show access to the capacity functions (subroutines).
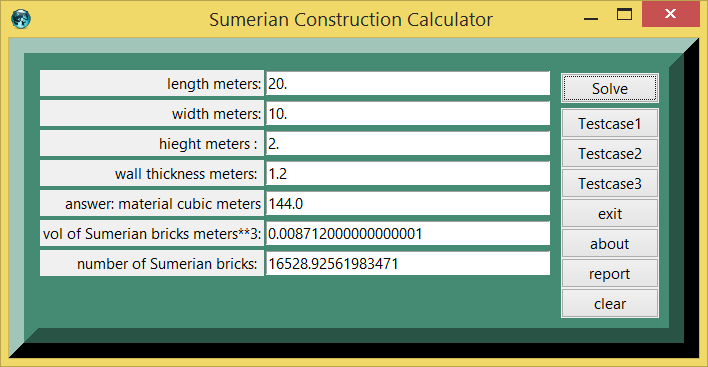
Testcase 1
| Four walled first temple | ||
|---|---|---|
| quantity | value | units |
| temple length | 20. | meters |
| temple width | 10. | meters |
| temple height | 5. | meters |
| temple wall thickness | 1.2 | meters |
| length brick | .33 | meters |
| width brick | .33 | meters |
| height brick | .08 | meters |
| answer: material volume | 144. | cubic meters |
| answer: brick volume | 0.0087 | cubic meters |
| answer:number of bricks | 1.65E4 | bricks |
Testcase 2
| 4 Walled Temple | ||
|---|---|---|
| quantity | value | units |
| temple length | 20. | meters |
| temple width | 20. | meters |
| temple height | 5. | meters |
| temple wall thickness | 1.2 | meters |
| length brick | .33 | meters |
| width brick | .33 | meters |
| height brick | .08 | meters |
| answer: material volume | 192. | cubic meters |
| answer: brick volume | 0.0087 | cubic meters |
| answer:number of bricks | 2.2E4 | bricks |
Testcase 3
| Single Wall | ||
|---|---|---|
| quantity | value | units |
| temple length | 27. | meters |
| temple width | 0. | meters |
| temple height | 3. | meters |
| temple wall thickness | 0.5 | meters |
| length brick | .33 | meters |
| width brick | .33 | meters |
| height brick | .08 | meters |
| answer: material volume | 71.28 | cubic meters |
| answer: brick volume | 0.0087 | cubic meters |
| answer:number of bricks | 8.181E3 | bricks |
Testcase 4
| mw 124 tablet, potters report | Ur III | ||
|---|---|---|---|
| quantity | values | units | comment |
| reeds as fuel | 1800 | kilograms | potters report |
| pottery vessels | 2000 | vessels | potters report |
| clay objects | 12 | objects | potters report |
| workdays at pottery shop | 3604 | workdays | potters report |
| 1135 kg wood for 3800 kg of clay | 1880's clamp kiln | ||
| 1135/1800 = 3800/x | proportions | ||
| x= 3800*1800/1135, 6026.4 kg of clay | modern equation estmating clay | ||
| days digging clay 6026.4 kg of clay /6 1004 days | coefficient equation | ||
| days forming clay 6026/(288*.33*.33*.08) = 2401 days | coefficient equation | ||
| 3404 days total re reported 3604 | comparison |
Testcase 5
| trial Sumerian "Orchard House" with some assumptions | |||||||
|---|---|---|---|---|---|---|---|
| quantity etc | length cubits | width cubits | height cubits | length meters | width meters | height meters | comment |
| back wall | 23 | 1/2 | 3 | 11.5 | 0.249 | 1.493 | back wall |
| front wall | 21 | 1/2 | 2 | 10.45 | 0.249 | 0.995 | front with door opening,3 m. finished? |
| side wall | 60+1/2 | 1/2 | 3 | 30.11 | 0.249 | 0.995 | back wall |
| combo side wall & garden wall | 255 | 2/3 | 3 | 126.9 | 0.3314 | 1.49 | combo, "2/3c" probably baked brick |
| end of day totals | quantity | value | comment | ||||
| workers | 74 +5/6 for 1 day | turned in day one | |||||
| its grain | 598+ 2/3 liters | turned in one day one | |||||
| food wages | 8 liters | turned in one day one | |||||
| running eTCL calculator & assumptions | quantity | value | comment | ||||
| house front meters | 11.5 | modern estimate | |||||
| house side meters | 30.11 | modern estimate | |||||
| house wall thickness | 0.3114 | assuming all baked, modern estimate |
| house surface area | 346.26 sq. meters | modern estimate | |||||
| wall volume of 4 walls | 77.7 cubic meters | modern estimate | |||||
| number of baked bricks | 8924 | assuming all baked (2/3c) type, modern estimate | |||||
| orchard size | 60*60 meters | garden wall would enclose 60*60 sq. meters or 4*60 perimeter of square iku, modern assumption |
Testcase 6
| testcase number: | 6 |
|---|---|
| temple of Sara at Umma, UrIII: | 6 |
| temple length: | 18. |
| temple width meters: | 3. |
| temple height meters: | 6.5 |
| temple thickness meters: | .87 |
| material volume cubic meters: | 237.510 |
| brick volume cubic meters: | 0.0087 |
| number of bricks: | 27262.396 |
ScreenShots Section:
References:
- Cities of the Ancient World: [L1 ]
- Canal regulators in Ancient Sumer www.aulaorientalis.org/AuOr%20escaneado/AuOr%2020-2002/1/6.pdf
- Geometrical coefficients [L2 ]
- Problem texts F-J: Excavations [L3 ]
- Problem texts N-Q: Bricks [L4 ]
- Cuneiform mathematics [L5 ]
- Mesopotamian units [L6 ]
- triangle rule akira.ruc.dk/~jensh/publications/Pythrule.pdf
- The Ricardian Trade Model www.econ.iastate.edu/classes/econ355/choi/ric.htm
- History of Old Babylonian mathematicswww.mpiwg-berlin.mpg.de/Preprints/P436.PDF
- Friberg eprints.soas.ac.uk/10098/29/16_Friberg-George.pdf
- Yale University Tell Leilan Project leilan.yale.edu/pubs/files/Ristvet2007PowerArch.pdf
- Project Documentation research.ncl.ac.uk/forum/v5i1/gelder.pdf
- Accounting for Change in Early Mesopotamia,Eleanor Robson,All Souls College, Oxford
- includes Gaes brick piles Sumerian Coefficients in the Pottery Factory and Calculator Demo Example
Appendix Code
appendix TCL programs and scripts
# pretty print from autoindent and ased editor
# Sumerian construction calculator
# written on Windows XP on eTCL
# working under TCL version 8.5.6 and eTCL 1.0.1
# gold on TCL WIKI , 24mar2014
# comment follows from gold, 12Dec2018
# pretty print from autoindent and ased editor
# Sumerian Construction Calculator V2
# written on Windows XP on TCL
# working under TCL version 8.6
# Revamping older program from 2014.
# One of my early TCL programs on wiki.
package require Tk
namespace path {::tcl::mathop ::tcl::mathfunc}
frame .frame -relief flat -bg aquamarine4
pack .frame -side top -fill y -anchor center
set names {{} {length meters:} }
lappend names {width meters:}
lappend names {height meters : }
lappend names {wall thickness meters: }
lappend names {answers: material cubic meters}
lappend names {vol of Sumerian bricks cubic meters:}
lappend names {optional:}
lappend names {number of Sumerian bricks: }
foreach i {1 2 3 4 5 6 7 8} {
label .frame.label$i -text [lindex $names $i] -anchor e
entry .frame.entry$i -width 35 -textvariable side$i
grid .frame.label$i .frame.entry$i -sticky ew -pady 2 -padx 1 }
proc volx { aa bb cc } {
set volem [* $aa $bb $cc ]
return $volem
}
proc about {} {
set msg "Calculator for Sumerian Construction V2
from TCL ,
# gold on TCL Club, 12Dec2018"
tk_messageBox -title "About" -message $msg }
proc self_help {} {
set msg " Sumerian Construction V2
from TCL Club ,
# self help listing
# problem, Sumerian Construction V2
# 4 givens follow.
1) length meters:
2) width meters:
3) height meters:
4) wall thickness meters:
# Recommended procedure is push testcase
# and fill frame,
# change first three entries etc, push solve,
# and then push report.
# Report allows copy and paste
# from console to conventional texteditor.
# For testcases, testcase number is internal
# to the calculator and will not be printed
# until the report button is pushed
# for the current result numbers.
# >>> copyright notice <<<
# This posting, screenshots, and TCL source code is
# copyrighted under the TCL/TK license terms.
# Editorial rights and disclaimers
# retained under the TCL/TK license terms
# and will be defended as necessary in court.
Conventional text editor formulas
or formulas grabbed from internet
screens can be pasted into green console.
# gold on TCL Club, 12Dec2018 "
tk_messageBox -title "Self_Help" -message $msg }
proc calculate { } {
global answer2
global side1 side2 side3 side4 side5
global side6 side7 side8 testcase_number
global tlength
global tlengthsq surfacearea
global tlengthx
incr testcase_number
set tlength $side1
set twidth $side2
set theight $side3
set tthickness $side4
set brickl 0.33
set brickw 0.33
set brickt 0.08
set brickvolx [volx 0.33 0.33 0.08]
set wallside [volx $tlength $theight $tthickness]
set wallfront [volx $twidth $theight $tthickness]
set totalvolx [+ [* $wallside 2. ] [* $wallfront 2. ]]
set brickvol [* 0.33 0.33 0.08]
set bricknumx [/ $totalvolx $brickvol ]
set side5 $totalvolx
set side6 $brickvol
set side8 $bricknumx
}
proc fillup {aa bb cc dd ee ff gg hh} {
.frame.entry1 insert 0 "$aa"
.frame.entry2 insert 0 "$bb"
.frame.entry3 insert 0 "$cc"
.frame.entry4 insert 0 "$dd"
.frame.entry5 insert 0 "$ee"
.frame.entry6 insert 0 "$ff"
.frame.entry7 insert 0 "$gg"
.frame.entry8 insert 0 "$hh"}
proc clearx {} {
foreach i {1 2 3 4 5 6 7} {
.frame.entry$i delete 0 end } }
proc reportx {} {
global side1 side2 side3 side4 side5
global side6 side7 side8
global testcase_number
console eval {.console config -bg palegreen}
console eval {.console config -font {fixed 20 bold}}
console eval {wm geometry . 40x20}
console eval {wm title . " Sumerian Construction V2 Report, screen grab and paste from console 2 to texteditor"}
console eval {. configure -background orange -highlightcolor brown -relief raised -border 30}
console show;
puts "%|table $testcase_number|printed in| tcl wiki format|% "
puts "&| quantity| value| comment, if any|& "
puts "&| testcase number:|$testcase_number | |&"
puts "&| $side1 :|length meters: | |&"
puts "&| $side2 :|width meters:| |& "
puts "&| $side3 :|height meters:| |& "
puts "&| $side4 :|wall thickness meters: | |&"
puts "&| $side5 :|answers : material cubic meters | |&"
puts "&| $side6 :|vol of Sumerian bricks cubic meters: | |&"
puts "&| $side7 :|optional: | |&"
puts "&| $side8 :|number of Sumerian bricks: | |&"
}
frame .buttons -bg aquamarine4
::ttk::button .calculator -text "Solve" -command { calculate }
::ttk::button .test2 -text "Testcase1" -command {clearx;fillup 20. 10. 2. 1.2 144. .0087 0. 16500. }
::ttk::button .test3 -text "Testcase2" -command {clearx;fillup 20. 20. 2. 1.2 192. .0088 0. 22000. }
::ttk::button .test4 -text "Testcase3" -command {clearx;fillup 30. 10. 2. 1.2 192. .0087 0. 22000. }
::ttk::button .clearallx -text clear -command {clearx }
::ttk::button .about -text about -command about
::ttk::button .self_help -text self_help -command { self_help }
::ttk::button .cons -text report -command { reportx }
::ttk::button .exit -text exit -command {exit}
pack .calculator -in .buttons -side top -padx 10 -pady 5
pack .clearallx .cons .self_help .about .exit .test4 .test3 .test2 -side bottom -in .buttons
grid .frame .buttons -sticky ns -pady {0 10}
. configure -background aquamarine4 -highlightcolor brown -relief raised -border 30
wm title . "Sumerian Construction Calculator V2 " Pushbutton Operation
For the push buttons, the recommended procedure is push testcase and fill frame, change first three entries etc, push solve, and then push report. Report allows copy and paste from console.
For testcases in a computer session, the eTCL calculator increments a new testcase number internally, eg. TC(1), TC(2) , TC(3) , TC(N). The testcase number is internal to the calculator and will not be printed until the report button is pushed for the current result numbers (which numbers will be cleared on the next solve button.) The command { calculate; reportx } or { calculate ; reportx; clearx } can be added or changed to report automatically. Another wrinkle would be to print out the current text, delimiters, and numbers in a TCL wiki style table as
puts " %| testcase $testcase_number | value| units |comment |%" puts " &| volume| $volume| cubic meters |based on length $side1 and width $side2 |&"
Initial Console Program
# pretty print from autoindent and ased editor
# Sumerian bricks for
# special project of King Amar Suen
# written on Windows XP on eTCL
# working under TCL version 8.5.6 and eTCL 1.0.1
# gold on TCL WIKI , 24jul2014
package require Tk
namespace path {::tcl::mathop ::tcl::mathfunc}
console show
set diameter .5
set height .08
set length .66
set length .66
set bricknumber 4.32E5
set brickmass [ * $bricknumber .66 .66 .08 ]
set pitchmass [ / $brickmass 6. ]
set workdays [ / $bricknumber 288. ]
puts "brick mass $brickmass"
puts "pitch mass $pitchmass"
puts "man workdays $workdays"
Comments Section
Please include your wiki MONIKER and date in your comment with the same courtesy that I will give you.Thanks, gold 12Dec2018
| Category Numerical Analysis | Category Toys | Category Calculator | Category Mathematics | Category Example | Toys and Games | Category Games | Category Application | Category GUI |