Version 2 of Web Scraping with htmlparse
Updated 2012-12-04 17:53:33 by JorgeJM 4 Dec 2012 - Here is a minimal example of Web scraping using htmlparse
As I am a RS fan, I am getting a list of all his recent projects.
- This is an unfinished code just to show the overall mechanism.
- notice that I am getting just one link per bullet, so, for example, I am missing the link for A pocket Wiki, which is the second link on the 5th bullet. see how just Profiling with execution traces is shown.
- also, notice the error message "node "" does not exist in tree "t"" when there is no link on the bullet, as in "simplicite"
getting as many links per bullet could be a good exercise for the reader.
As a side note, I use LemonTree branch to easily find the location of the bulleted list block that I am parsing.
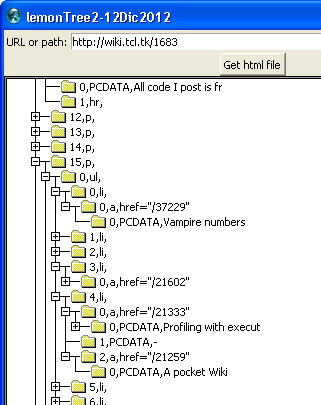
console show
package require struct
package require htmlparse
package require http
proc parse {} {
::struct::tree t
set url "http://wiki.tcl.tk/1683"
set http [::http::geturl $url]
set html [::http::data $http]
htmlparse::2tree $html t
htmlparse::removeVisualFluff t
htmlparse::removeFormDefs t
set base [walk {1 15 0}]
puts "data: [t get $base data]"
puts "type(tag): [t get $base type]\n"
set bulletIx [walkf $base {0}]
while {$bulletIx != {}} {
set link [t get [walkf $bulletIx {0}] data]
#set title [t get [walkf $bulletIx {0 0}] data]
catch {t get [walkf $bulletIx {0 0}] data} title
puts "$link: $title"
update
set bulletIx [t next $bulletIx]
}
t destroy
return
}
proc walkf {n p} {
foreach idx $p {
if {$n == ""} {break}
set n [lindex [t children $n] $idx]
}
return $n
}
proc walk {p} {
return [walkf root $p]
}
parse