Version 9 of Web Scraping with htmlparse
Updated 2015-01-11 14:22:15 by dbohdanJM 4 Dec 2012 - Here is a minimal example of Web scraping using htmlparse
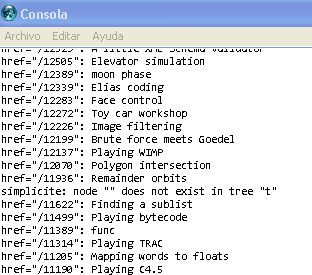
As I am a RS fan, I am getting a list of all his recent projects.
- This is an unfinished code just to show the overall mechanism.
- notice that I am getting just one link per bullet, so, for example, I am missing the link for A pocket Wiki, which is the second link on the 5th bullet. see how ONLY Profiling with execution traces is being listed.
- also, notice the error message "node "" does not exist in tree "t"" when there is no link on the bullet, as in "simplicite"
getting as many links per bullet could be a good exercise for the reader.
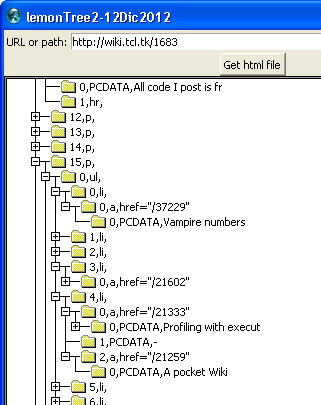
As a side note, I used LemonTree branch to easily find the location of the bulleted list block that I am parsing.
Accessing data by walking the tree
package require struct
package require htmlparse
package require http
namespace eval ::scraper {
# The tag at $startNodePath should be a <ul> with its children having the
# structure of <li><a href="...">...</a><li>.
proc parse-list-of-links {url startNodePath} {
set documentTree [::struct::tree]
set conn [::http::geturl $url]
set html [::http::data $conn]
htmlparse::2tree $html $documentTree
htmlparse::removeVisualFluff $documentTree
htmlparse::removeFormDefs $documentTree
set base [walk $documentTree $startNodePath]
puts "data: [$documentTree get $base data]"
puts "type(tag): [$documentTree get $base type]\n"
# Start with the first child of the base tag.
set li [walkf $documentTree $base {0}]
while {$li ne ""} {
set link [$documentTree get [walkf $documentTree $li {0}] data]
catch {$documentTree get [walkf $documentTree $li {0 0}] data} title
puts "$link: $title"
# Go from the current li to its sibling node.
set li [$documentTree next $li]
}
$documentTree destroy
return
}
proc walkf {tree startNode path} {
set node $startNode
foreach idx $path {
if {$node eq ""} {
break
}
set node [lindex [$tree children $node] $idx]
}
return $node
}
proc walk {tree path} {
return [walkf $tree root $path]
}
}
::scraper::parse-list-of-links "http://wiki.tcl.tk/1683" {1 15 0}dbohdan 2015-01-11: I found the example code above hard to understand, so I updated it with some comments as well as variable and proc names that I think clarify what the script does at each step. JM, I hope you don't mind my changes.
Accessing data with TreeQL
dbohdan 2015-01-11: The following script scraps and prints exactly the same data as the one above, except in a different order, using TreeQL queries.
package require struct
package require fileutil
package require htmlparse
package require http
package require treeql 1.3
proc parse-treeql {url} {
set documentTree [::struct::tree]
set conn [::http::geturl $url]
set html [::http::data $conn]
htmlparse::2tree $html $documentTree
htmlparse::removeVisualFluff $documentTree
htmlparse::removeFormDefs $documentTree
treeql q1 -tree $documentTree
treeql q2 -tree $documentTree
#puts [$documentTree serialize]
set i 0
q1 query tree withatt type ul
set ul1 [lindex [q1 result] 2]
q1 query replace $ul1 children children map x {
# for each li > a
q2 query replace $x get data
set link [lindex [q2 result] 0]
q2 query replace $x children get data
set title [lindex [q2 result] 0]
if {$title ne ""} {
puts "$link: $title"
}
}
q1 discard
q2 discard
$documentTree destroy
return
}
parse-treeql "http://wiki.tcl.tk/1683"